February 5, 2021
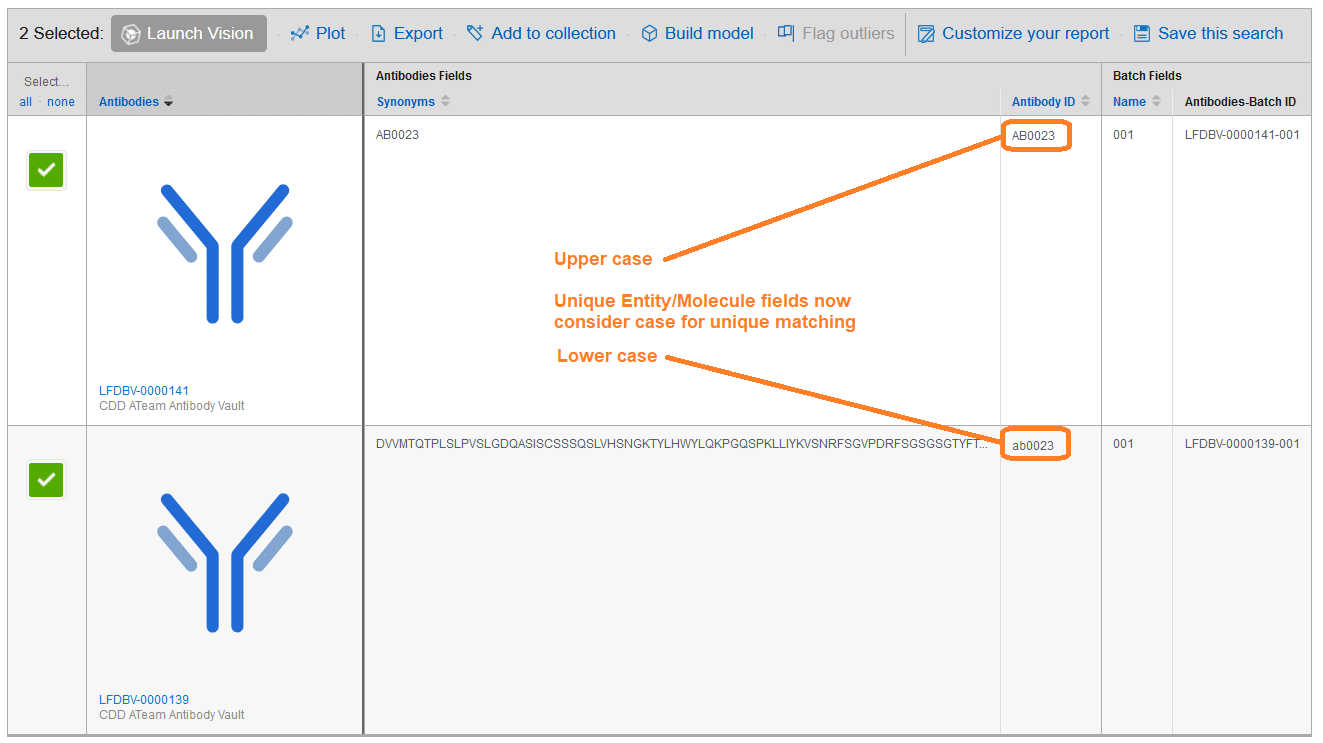
Unique Entity/Molecule Fields are now Case Sensitive
Upper and lower case characters are considered different and can be registered as separate values into any Entity/Molecule field marked as “Must be unique”. This expands the utility of unique Entity/Molecule fields as top-level parent-record identifiers when chemical structures are not being registered. For example, upper and lower case letters can be used in a sequence to:- Indicate amino acid or nucleotide modifications or mutations (e.g.: methylation)
- Emphasize a specific domain within a sequence (e.g.: binding domain)
- Denote the insert in a vector backbone
- Mark low confidence nucleotides from sequencing results
- Distinguish between registered RNA and DNA sequences